고정 헤더 영역
상세 컨텐츠
본문
R언어 개발 환경 구축 및 실습
1. R언어 개념, Python과의 비교
2. R설치, 개발환경인 R studio 설치
3. R간단한 실습
ADsP(데이터분석 준전문가), 빅데이터 기사 공부 겸, 그리고 통계와 데이터를 다루기 위한 언어인 R언어에 대해 알아보고 개발 환경을 구축해 봅니다. 가볍게 사용해 보니 IDE가 쉽게 설치되는 것이 다른 언어에 비해 상당히 마음에 들고, 확실히 수학적 통계, 계산, 그래프에 중점이 되어있는 언어라는 게 느껴집니다.
블로그 포스팅은 복습 겸, R언어를 어떻게 사용하는지 가볍게 배우는 수준이라서, 정식으로 배우고 싶으시다면 따로 공부하셔야 합니다.
1. R언어 개념, Python과의 비교
R언어는 S언어를 기반으로 만들어진 통계관련 처리에 적합한 프로그래밍 언어이다.
Python 은 C언어를 기반으로 만들어진 범용 프로그래밍 언어이다.
구인 구직 사이트를 보면
데이터 분석가, AI 관련, 금융권에서 [R, python]과 같은 데이터 분석 프로그래밍 능력자를 찾는다.

- R과 Python의 공통점
- 오픈소스인 GPL 라이센스
- 인터프리터 방식
- R과 Python의 차이점
| R 언어 | Python | |
| 기반 | S언어(1976년, 벨 연구소) | C언어(1972년, 벨 연구소) |
| 간단 역사 | 만든이 뉴질랜드 오클랜드 대학 교수 2명 로버트 젠틀맨, 로스 이하카 (Robert Gentleman, Ross Ihaka) 1993년 뉴질랜드에서 프로젝트 시작 1995년 0.16.1 버전 오픈소스로 첫 배포 2000년 정식 1.0.0 버전 릴리스 |
만든이 네덜란드 귀도 반 로섬 (Guido van Rossum) 1989년 12월 크리스마스 휴가 기간 동안 개발 시작 1991년 0.9.0 버전 릴리스 1994년 정식 1.0 버전 릴리스 |
| 주된 목적 | 통계 모델링, 데이터 분석, 그래프에 특화 | 범용 프로그래밍 언어 + 머신러닝, 딥러닝 |
| 함수형 | 함수형 | 함수 및 객체지향 혼합 |
둘 다 빅데이터를 다루는데 사용하는 언어라서 비교가 많이 된다.
한국의 기사시험 '빅데이터 분석기사'에서도 실기 시험에서 R언어와 python언어를 선택할 수 있다.
2. R설치, 개발환경인 R studio 설치
R설치
공식홈페이지 https://www.r-project.org/
R: The R Project for Statistical Computing
The R Project for Statistical Computing Getting Started R is a free software environment for statistical computing and graphics. It compiles and runs on a wide variety of UNIX platforms, Windows and MacOS. To download R, please choose your preferred CRAN m
www.r-project.org
Download 탭의 CRAN 클릭 → 미러서버 korea에서 https://cran.yu.ac.kr/ 클릭 → 윈도우라면 Download R for Windows 클릭 → base 클릭 → Download R-4.5.0 for Windows (86 megabytes, 64 bit) 클릭하여 다운로드
귀찮다면 https://cran.yu.ac.kr/bin/windows/base/R-4.5.0-win.exe 링크를 한번에 클릭하여 받아도 된다.
(게시글의 모든 링크는 작성자가 확인하고 올리고 있습니다.)
설치하면 R4.5.0 이 설치된 것을 확인 할 수 있다.


이렇게 사용할 수도 있지만 좀 불편하니 IDE(Integrated Development Environment, 통합개발환경)를 설치해본다.
Rstudio 설치
Rstudio 홈페이지 https://posit.co/download/rstudio-desktop/
에서 2: Install RStudio 아래 Download RStudio Desktop for windows를 클릭하여 다운 받는다.
또는 현재 최신버전 다운로드 링크 : https://download1.rstudio.org/electron/windows/RStudio-2024.12.1-563.exe
기본값으로 설치하면 된다.
Rstudio가 설치되고 아래와 같이 사용할 수 있다.

파이썬을 배웠다면 비슷한 부분이 많아 어렵지 않게 사용할 수 있다.
3. R간단한 실습
콘솔에서 Ctrl + L을 입력하면 콘솔창이 clear된다.
우측 상단에 저장된 변수 값이 보인다.
파이썬과 비슷한 면이 있어서 파이썬을 알면 문법은 금방 배울 수 있다.
- a <- 123 또는 a = 123 처럼 변수 선언 및 값 할당이 가능하다.
- x %% y # 나눈 나머지
- x %/% y # 몫
- 주석은 # 이다.
- 변수 삭제는 rm(변수명)이다.
- 모든 변수 삭제 rm(list=ls())
- class(변수명) 데이터 타입을 알 수 있다.

> class('bonobono')
[1] "character"
>
> bonobono <- 1234
>
> class(bonobono)
[1] "numeric"
>
> a <- 55
>
> c = bonobono + a
>
> print(c)
[1] 1289
>
> class(c)
[1] "numeric"
> class("TRUE")
[1] "character"
> class(TRUE)
[1] "logical"
> print(TRUE)
[1] TRUE
> print(1+TRUE)
[1] 2
>
R의 데이터 구조
벡터, 행렬(matrix), 배열(array), 리스트, 데이터 프레임, 요인(factor)
①벡터 사용해 보기
벡터는 같은 데이터 타입을 가지는 원자 벡터가 있고, 서로 다른 타입을 담을 수 있는 재귀 벡터가 있다.
재귀 벡터는 결국 리스트이다. 일반적으로 벡터라고 말하면 원자 벡터이다.
벡터의 특징은 다른 타입을 섞으면 상위 타입으로 강제로 변환(coercion)하여 하나의 타입을 가지게 된다.
예를 들어 숫자와 문자를 벡터에 넣으면 전부 문자로 변환한다.
c()함수는 concatenate로서 데이터를 묶을 수있다.
c(7:9)는 7,8,9를 하나로 묶는 것을 의미한다.

②행렬 사용해 보기
matrix() 함수를 사용한다.
기본적으로 열(column)로 정렬되며, 행(row)으로 정렬하고 싶으면 byrow = T를 입력해준다.

③배열 사용해 보기
행렬이 2차원이라면 배열은 3차원 이상도 가능하다.
array함수에서 dim 옵션을 사용하면 차원을 결정할 수 있다.
dim=c(2,3,2)로 하면, 2*3*2 2행*3열*2면으로 3차원 배열을 설정한다.
개념상 육면체를 생각하면 된다.
행렬처럼 2차원 배열도 가능하고, 그 이상의 고차원 배열도 가능하다.

④리스트 사용해 보기
리스트의 특징 : 다른 데이터 타입을 넣을 수 있다.
※ 메모리 할당에 있어서 배열과 리스트 타입의 차이(연속, 불연속-링크)를 알고 있으면 자료구조 이해에 도움이 됩니다. 한 발 더 나아가 시간 복잡도, 공간 효율까지 고려 한다면 당신은 훌륭한 프로그래머입니다.
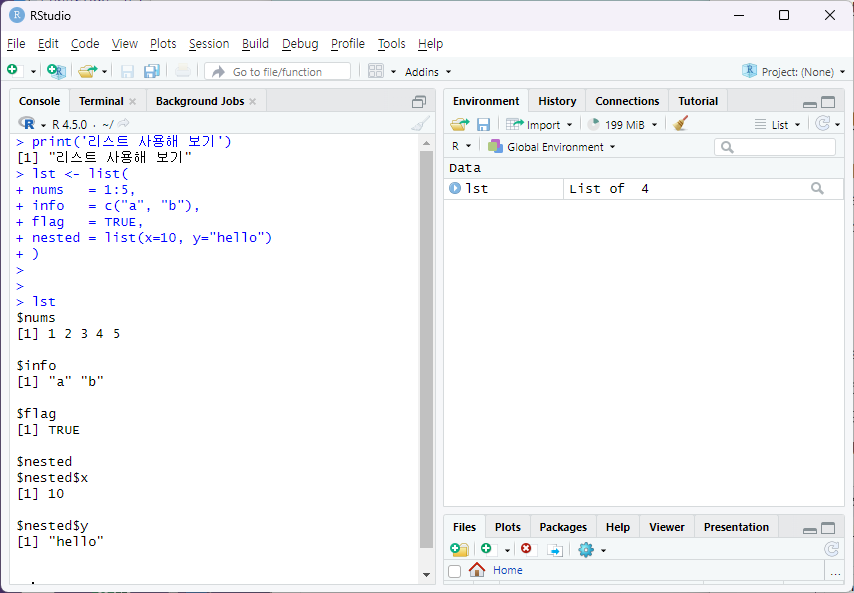
⑤데이터 프레임 사용해 보기
데이터 프레임은 길이가 같은 서로 다른 타입의 벡터(열)을 묶어 2차원 표 형태로 만든 구조이다.

⑥요인(factor) 사용해 보기
범주형(categorical) 데이터를 효율적으로 저장, 처리하기 위한 특별한 벡터이다.


print('factor 사용해 보기')
name <- c("릴리","해원","설윤","배이","지우","규진")
birth_years <- c(2002, 2003, 2004, 2004, 2005, 2006)
bloodtype <- c('O','O','A','B','AB','A')
#데이터프레임
df1 <- data.frame(
Name = name,
Birth = birth_years,
Btype = bloodtype,
stringsAsFactors = FALSE
)
#factor로 변환
df1$Name <- factor(df1$Name)
#혈액형은 levels 수준을 지정할 수도 있으니 지정해보기
df1$Btype <- factor(
df1$Btype,
levels = c("O","A","B","AB"),
ordered = FALSE
)
print(df1)
str(df1) #구조를 요약해서 출력
levels(df1$Btype) #factor에서 범주
table(df1$Btype) #출현 빈도
factor는 범주형 데이터를 다루기 위해 사용한다.
이렇게 R을 끝내긴 너무 아쉬우니 하드코딩으로 아무 그래프 하나만 그려본다.
통계청에서 GDP 자료를 찾아서 하드코딩 하였다.
# 실질 국내 총생산 입력
year <- 2015:2024
gdp_trillions <- c(
1.840, # 2015
1.898, # 2016
1.963, # 2017
2.026, # 2018
2.073, # 2019
2.058, # 2020
2.153, # 2021
2.212, # 2022
2.243, # 2023
2.288 # 2024
)
# 기본 산점도 + 선 그래프
plot(year, gdp_trillions,
type = "b", # 점(b) + 선(l) 함께 그리기
pch = 19, # 점 모양: 실린 원
lty = 1, # 선 타입: 실선
xlab = "연도", # x축 라벨
ylab = "실질 GDP (천조 원)", # y축 라벨
main = "한국의 국내 총생산 (2015–2024) [단위:조원]") # 제목

만약
plot.new()에서 다음과 같은 에러가 발생했습니다: figure margins too large
에러가 나온다면 우측 하단 그래프 출력 창이 너무 작아서 그런 것이니 우측 하단 윈도우 사이즈를 늘려주면 된다.
2024년 명목 국내 총생산은 2549조 원이고, 실질 국내 총생산은 2288조 원이다.
(※ 명목은 물가 변동 포함, 실질은 물가 변동 제외)
2024년 대한민국 예산은 약 650조 원이고, 부채는 약 1200조 원이다.
R을 배우면 경제 공부도 되는가보다.
끝.




